Online Accounts 2025: First Steps (Premium)
- Paul Thurrott
- Feb 10, 2025
-
12
Almost exactly 20 years ago, I approached my wife with a request. I needed to spend about $2000 on two 1 TB LaCie Bigger Disk Extreme external hard drives so that we could back up all our personal and work-related data, replicate it, and keep one of the two disks at my parent’s house nearby. 1 TB was an astronomical amount of storage at that time, and each unit had two physical disks for replication purposes, explaining the cost. And since this was a FireWire 800-based drive, a high-performance oddity of sorts, I also needed to get a FireWire 800 interface card for my Windows Server. But I came to her with data to support this need, and I had a plan. I would perform a full backup once each month and then swap out the drive with the one at my parent’s house, making another backup when I got the other disk back.
I needn’t have bothered. Within a few seconds of my spiel, my wife interrupted and said, we obviously need this, just buy it. And so I did. And for the next several years of that pre-cloud era, I did exactly what I said I was going to, I routinely backed up our data, swapping those big metal drives with their replicated contents between the two locations. That’s what we did back then. We backed up our data.
Well, that’s what we did after we had experienced some traumatic data loss, at least. As I first observed around this time, we tend to get religion only after something bad happens. It’s the visceral reaction to what was once theory but is now reality that provides the impetus for doing the right thing. And in this case, a hardware failure with a data drive was the trigger.
“Not that I needed the recent failure of my 30 GB data drive to remind me, but when you begin storing all of your digital photos, music, and videos on the PC, it’s more important than ever to back up regularly,” I wrote at the time. “I recommend a strict schedule, and if you use some sort of calendaring program such as Outlook, MSN Calendar, or Act, then be sure to set reminders so that you are prompted to make backups every week or so. While it’s possible to use the built-in backup in Windows, it might be better to back up to removable media such as CD or DVD. And make two copies, bringing one off-site if possible. Remember: You can never back up too much.”
My backup strategies changed in time, of course, as technology changed. By 2013, I was writing about what I called “zero data,” an effort to reduce my reliance on local storage and move as much of my data as possible to the cloud. This was early days for this sort of thing–I’m surprised I was calling it “the cloud” at the time, and it of course received pushback from an audience, then as now, stuck in traditional ways of doing things. Some “have misinterpreted this to mean that I will be ceding control of my content to cloud providers that may or may not have my best interests at heart,” I wrote at the time, a line that has obvious parallels to today. “More to the point, it’s important to have multiple copies of your data, for redundancy purposes. This is not about throwing it all away.”
It was, I wrote, “about differentiating between sync, storage, and backup.”
By this point, I had moved past the Lacie drives. Here is how I described my data backup strategy in 2013.
“I don’t want to lose my archives. My Windows Server-based home server duplicates this content locally, and backs it up locally, both of which preserve the information on multiple physical hard drives in my home. Because it’s backed up to Crashplan, there is also an offsite backup of the data. But my long term goal for this ‘archive’ of documents is to get it all out of my home. And that means two cloud providers, because I feel that this information, while rarely accessed, is still important. The Crashplan backup can sit there, but I’m looking into a secondary service, perhaps Amazon Glacier, as well. Once I get that data into two cloud services, I can decommission it locally.”
As for non-archived data, my “current” work, “I have a number of articles and article series ongoing all the time. I used to store these things on the server. But in 2012, with the advances in SkyDrive and the SkyDrive desktop application, I’ve moved my current work set to SkyDrive. This is replicated across all of my current PCs and, not coincidentally, to that Windows 8-based “home server” PC. I’m organizing things quite a bit differently now, but at the moment, I have my last two to three months’ worth of content available there, and I’m thinking that over time, I’ll begin pushing the oldest SkyDrive-based content—perhaps stuff older than three or six months—to a deep archive in Crashplan, Glacier, and/or whatever.”
It is fascinating to me to see how things changed–and, in many ways, stayed the same–over the years. My storage needs have only risen, of course, but technology has kept pace with that. And the way I organize my data today, with regard to data storage for current and archived personal information and work, has likewise evolved. Thanks to my recent escapades with YouTube, it’s about to evolve yet again.
The specifics and timing don’t matter, but between the 2013 and today, I moved from a series of what I’ll call Windows/Windows Server-based “home servers” to a simpler and more cost efficient NAS (network attached storage) device. But over time, even the NAS seemed like a mostly unnecessary complexity, and as the model I chose became increasingly out of date and was eventually unsupported, I was relying more on cloud services–Google and Microsoft cloud services, for consumers and businesses, in both cases–and much less on local storage. At a high level, the theory was unchanged: I could replicate my archived content to multiple places, just as I had done 20 years ago with those hard drives. But now most of those places were in the cloud.
My daily work, now as in 2012/2013, is all about sync. Using either Google Drive or OneDrive (the former SkyDrive), I rely on the local PC sync capabilities of these services to ensure that I can access my current work data–the documents and books I’m working on right now–on whatever PCs I use. I can work on a laptop in the living room, walk into the home office and wake up my PC there, and just keep working on the same content immediately. Generally speaking, this has been incredibly reliable, and that’s been even more true of Google Drive than OneDrive, though both are good in that capacity.
My most recent thinking on this topic can be found scattered throughout this site, but I will point to Don’t Be a Statistic (Premium) and Roll Your Own Windows Time Machine (Premium), both from 2023, as perhaps the most representative. My Digital Decluttering series from 2023/2024 also touches on this topic because it involves me consolidating content like digital photos, home videos, my work and personal archives, and more, and then replicating the organized results to multiple places. The simple way to think about this is that I don’t really back up in a traditional sense these days, nor do I see a need for that. Instead, I replicate the organized archives of whatever content to multiple places, and my daily work syncs between the cloud and several PCs. When my daily work is completed, I archive it. And on some schedule, that newly archived content is likewise replicated to those multiple places as needed.
This system works for me. But the YouTube issue I (over) documented in From the Editor’s Desk: Online Accounts, a Cautionary Tale (Premium) was a wake-up call similar to the one I had in 2004 when I lost that 30 GB data drive. It was an important reminder that the Big Tech companies that own the clouds I rely on do not care about me or my data. And that they could, at any time, pull the plug, locking me out of my accounts and that data. Whether this happens for good reason–perhaps I violate some terms of service–or not, as per my YouTube experience, does not matter. What matters is the unpredictable loss of control and that it could strike at any time.
With that in mind, I took a new look at the online accounts that I use to access and contain my data. And I discovered some areas I had previously overlooked. On some level, my current system for replicating work archives, my photo collection, and other important data between multiple places is as sound as ever. But on some other level, not having complete control over that data is a problem. There is also data I’ve never thought to back up, like the videos I’m hosting on the Thurrott.com channel on YouTube, and that is a horrifically stupid oversight on my part. And there are other issues tied to these online accounts that I have to address, with the aim of recovering more elegantly should one of these companies screw me over again. I got lucky, really lucky, with the YouTube fiasco. I am going to try and not find myself in that position again, if possible.
I will spend a lot of time working on fixing these issues in 2025, and though I’m sure the plan will evolve as I step through this work, you can find my initial to-do list in Online Accounts 2025 (Premium). As I did 20 years ago, I discussed with her the two NAS devices I intend to buy this year, and as she did 20 years ago, she deferred to my thinking on this matter because this is my area of (relative) expertise. But it was important to me that she–and you–understand a subtle shift in emphasis here that, when you think about it, is not that subtle at all.
As I write this, I am using Google Drive as the primary (and, really, only) source for my current work. I have two major top-level folders, To-do (which maybe should be named Current) and Book, that are synced to my Google Drive cloud and to each of the PCs I use via the Google Drive desktop client. To-do contains all of my non-book work for Thurrott.com, Eternal Spring, and whatever else, and Book contains my books, which are each also synced into GitHub. (There is also a Code folder for .NETpad and my other developer projects, but that is in OneDrive.) I use month-named (2025-02, 2025-01, etc.) folders in Google Drive, as well, for archiving recently completed work. And those get pushed into all those replicated work archives I mentioned earlier on whatever schedule. I did some of that work in early January, for example, for obvious reasons.
Similarly, my wife and I back up all our phone-based photos and videos to Google Photos and OneDrive, and since that’s most of our photos, that’s most of the work that needs to happen there. But I because I previously organized our photo collection, and replicated that, each year, I will go through our respective photo sets from the previous year and consolidate those as well, and then push them into the replicated full photo collections. I’ve started, but not completed, that work for 2024. I hope to do that this month.
Beyond that is … other data. I have the videos in Thurrott.com that are suddenly top of mind. I have the videos I’ve made with my wife for Eternal Spring, which had been “backed up” to OneDrive until recently: They were eating into my OneDrive storage more than I wanted, and so I moved them into the OneDrive for Business storage associated with a Microsoft 365 Business account I maintain that is otherwise unused (well, aside from it also being one place where I store a work archive).
But in thinking about online accounts recently–OK, in obsessing over online accounts recently–it occurred that there is other data still. Passwords and passkeys associated with those online accounts, the means we use to authenticate ourselves so that we can access the content each contains. Single sign-on (SSO) associations between third-party online services and some of our Big Tech online accounts, especially Google. Contacts that, like passwords, are almost certainly spread between far too many content stores associated with different online accounts, each with different and contradictory data. And more. (Again, Online Accounts 2025 (Premium) has my first pass at this.)
And so here is the shift I intend to make this year.
I will continue using online services, of course. It’s 2025, there’s no going back to some old-school system in which I work locally, make backups, and move data around. But I will move to a system where online services, especially those controlled by Big Tech, will no longer be at the center. I will still use these services, but I will also lessen my day-to-day reliance on these companies that just do not give a crap about me, my company, or my personal or work-related data. I will get two NAS devices, put one in Mexico City and one in Pennsylvania, and they will replicate each other in real-time. As important, we will sync and replicate on the fly to these devices as well. In addition to backing up our phone-based photos to Google Photos and OneDrive, for example, we will do so to the NASes. As I write this, I’m not 100 percent sure about current work-related documents and other data, but I will also move the “main” copy of our personal and work archives to the NASes. In short, my use–our use–of Big Tech cloud services will move into a supporting role.
And yes, I will back up my Thurrott.com videos to these NASes. I can’t buy those devices until we return from Mexico: Electronics are much more expensive in this country than in the U.S., and the selection is smaller. But that will give me time to continue my research–I’m leaning towards Synology for all the obvious reasons, but I am as open as ever if there is a better option–and I can, at least, download those videos to see what I’m in for, storage wise.
I did that last week: Google offers a useful if tedious service called Takeout that lets you download any of the data associated with your Google account. And I know from experience–I used this service to download my photo collection at least twice during the Digital Decluttering work that the results are a mess and need to be organized. This wouldn’t be a big issue with the videos, of course. But I was curious how big the download would be.
So I found out.
I went to Google Takeout, deselected all the pre-selected data, and located YouTube in the list. As it turns out, it’s not just YouTube, it’s YouTube and YouTube Music. OK, fine. When you select this option, you can then configure the formats for various data types (though most of the choices here were grayed out) and which data is included. I wanted the videos, of course, but I also wanted some of the meta-data associated with those videos, which, I assumed, would include whatever titles and descriptions associated with each. Curious, I left all the options selected and just let it download a complete archive.
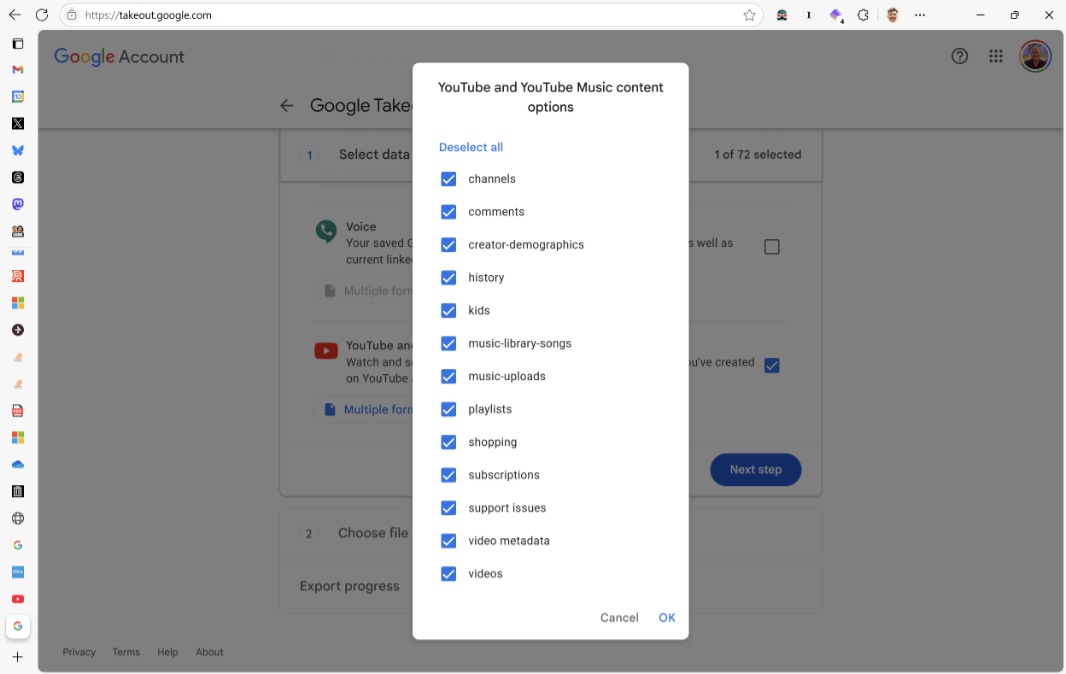
When you do this, you have no way of knowing how big that archive will be. Instead, you can then choose to download just this once or establish an export schedule, and, as important, whether to divide up the download into manageable chunks. Here, I always choose 2 GB downloads, so that larger exports will be divided into multiple files of that size. After that, it was a waiting game: Google would get my export ready and then email me when it was ready. The number of downloads would tell me the total size, at least in archived form (and, since these are videos, that would likely be close to the actual size on disk.)
It didn’t take long. The next morning, Google Takeout emailed me, and there were 63 files to download. As it turns out, some of them were individual videos, not ZIP files, that were bigger than 2 GB. But most were 2 GB ZIP files, and 2 times 63 is 126, so about 126 GB. That’s … nothing. It begs the question of why I never thought to make this backup in the past. But let’s stay focused on getting it right now. I started the downloads.
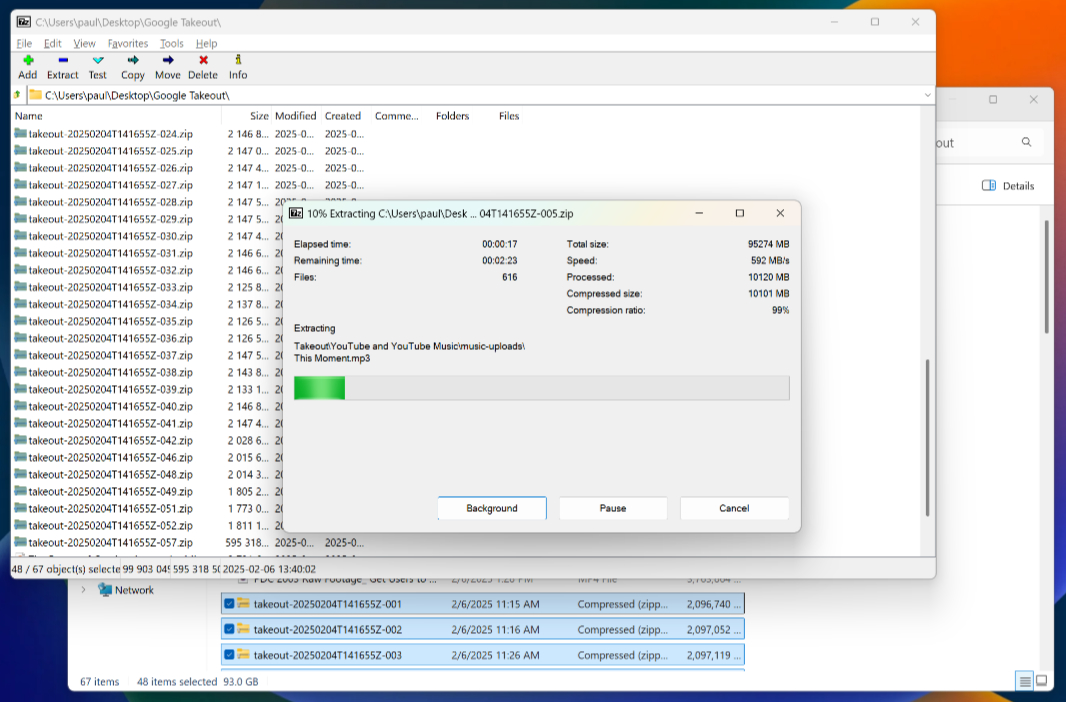
Downloading from Google Takeout is tedious, especially when you choose manageable 2 GB file sizes like I did. I did them in batches of 10, Ctrl + clicking on each link in turn so that they each opened a new tab. When the 10 downloads were down, I moved the ZIP files–and, eventually, the handful of bigger MP4 files–into a folder on my desktop. (I had chosen Surface Laptop 7 for this work since it has a large and underutilized 1 TB SSD drive.) It took the better part of the day, but by that evening I had the whole thing downloaded. 93 GB of the downloads were ZIP files, plus 5 or 6 MP4 files.
Windows includes built-in file archiving and unarchiving capabilities, of course, but it is inadequate for this work. So I downloaded 7-ZIP, open the folder with all the archives, and extracted them.
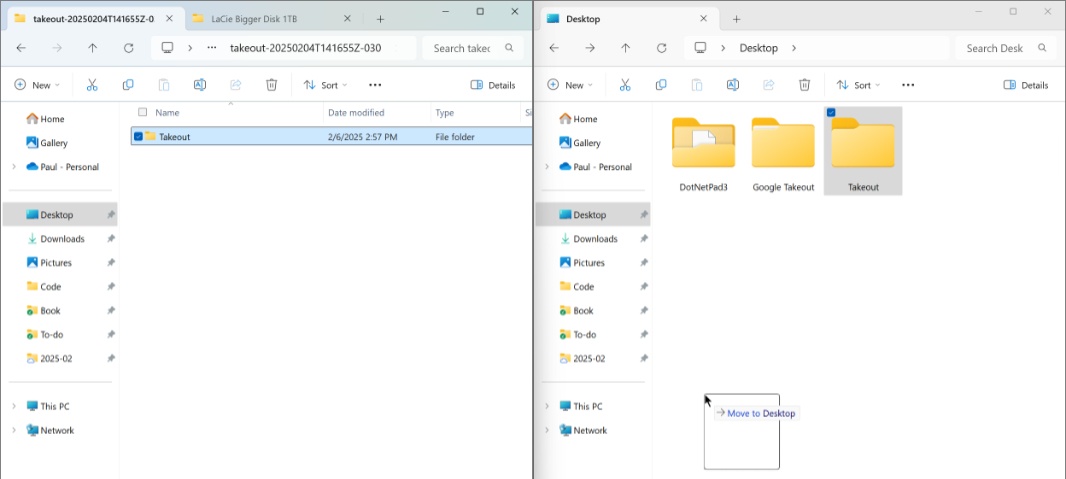
But that wasn’t the end of it. Each ZIP file unzipped into a unique folder (with names like takeout-20250204T141655Z-024, takeout-20250204T141655Z-025, and so on). And each of those folders had a subfolder named Takeout. Which had a subfolder named YouTube and YouTube Music. Which then had some subset of folders like channels, comments, history, live chats, and several others. Sigh.
There is probably a way to get 7-ZIP to more elegantly combine those folders into a single structure. But I just did it manually, using side-by-side File Explorer windows and drag and drop. On the left side, I navigated into each folder in turn and dragged the Takeout folder it contained into the folder on the right.
This was also tedious, but it went fairly quickly. In the end, the unzipped contents of the export was 142 GB. Still quite manageable, but also larger than the true number. This export included non-Thurrott.com videos, music I had uploaded to YouTube Music, and other extraneous data. The videos folder was just 94.5 GB, and there are 310 video files. Quite manageable.
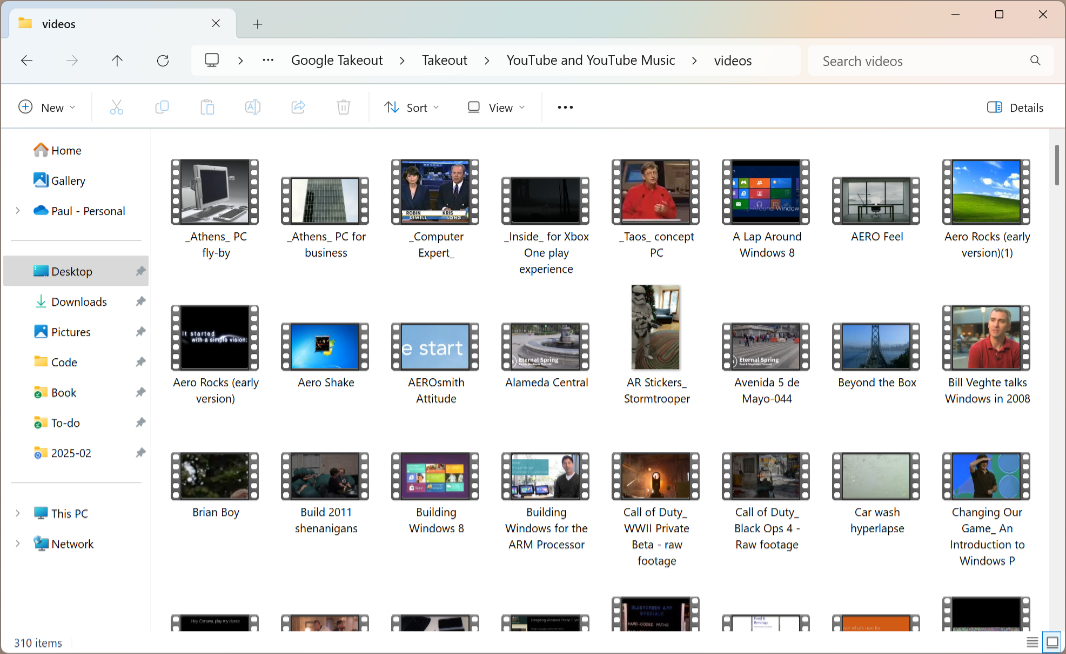
So manageable, in fact, that I decided to upload them temporarily to a few different online accounts. You know, just in case.
That said, this is only the videos I uploaded. It doesn’t include the many First Ring Daily videos that Brad has uploaded. So that will be a fun project to figure out soon as well.
As for the video metadata, I hope to never have to ever re-upload this content. That folder contains several CSV files, and the data is all in there, but … yikes. That will be a fun day.
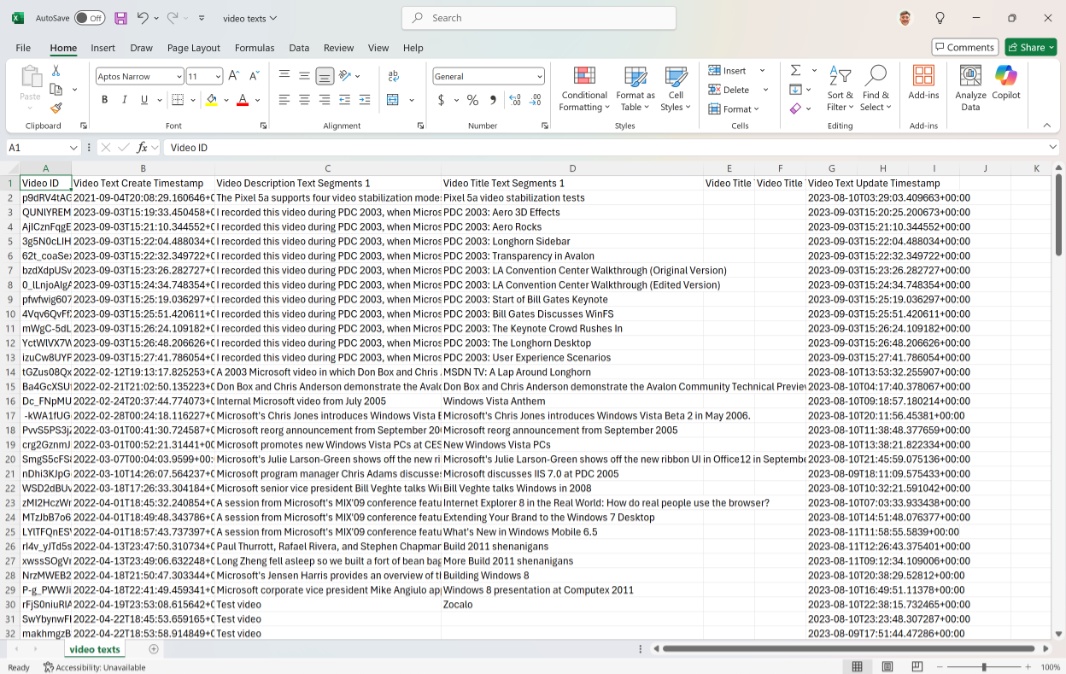
But at least I have my uploaded now. First Ring Daily is next. And when the day comes that I begin my NAS migration, this will be among the data that I store there. And keep up-to-date on whatever schedule. Perhaps I will schedule that through Google Takeout. It doesn’t matter.
More soon. There is a lot more work to do here, and I am not screwing around with this stuff anymore.
Gain unlimited access to Premium articles.
With technology shaping our everyday lives, how could we not dig deeper?
Thurrott Premium delivers an honest and thorough perspective about the technologies we use and rely on everyday. Discover deeper content as a Premium member.